

서울대, 한국어 특화 LLM 개발…AI 주권 시대 앞당긴다
이재진 교수팀, Llama 기반 한국어 특화 모델·토크나이저·벤치마크 전격 공개
){kind=link}
){kind=link}
){kind=link}

한국연구재단은 서울대 이재진 교수 연구팀이 영어 기반 Llama 모델을 개량해 한국어 특화 LLM ‘Llama-Thunder-LLM’과 전용 토크나이저 ‘Thunder-Tok’, 한국어 LLM 성능 평가 벤치마크 ‘Thunder-LLM’을 개발해 온라인에 공개했다고 밝혔다.
LLM은 방대한 텍스트 데이터를 학습해 인간의 언어를 이해하고 생성하는 인공지능 모델이다. 하지만 학습 데이터 확보와 개발 비용 부담으로 인해 대학이나 중소 연구기관에서는 독자 개발이 어려웠다.
연구팀은 3TB 규모의 한국어 웹 데이터를 수집·전처리한 뒤, 기존 영어 Llama 모델에 연속 학습과 사후 학습을 결합해 한국어 성능을 대폭 강화했다. Thunder-Tok 토크나이저는 한국어 문법 특성을 반영해 토큰 수를 기존 대비 44% 절감, 추론 속도와 학습 효율을 높였다.
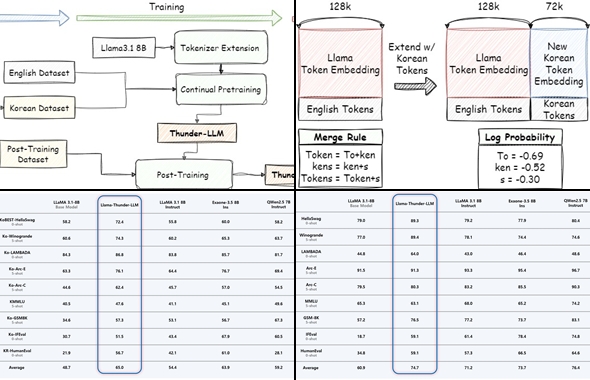
또한 한국어 벤치마크 데이터셋을 구축해 한국어 LLM 성능을 객관적으로 평가할 수 있는 기반도 마련했다. Thunder-LLM 벤치마크는 영어 벤치마크를 기계 번역 후 전문가 검수와 현지화를 거쳐 완성됐으며, 문학적 문맥 이해 평가용 Ko-LAMBADA 데이터셋은 한국어 특성에 맞춰 새롭게 설계했다.
이재진 교수는 “학계도 자주적인 LLM 개발이 가능함을 보여준 연구”라며, “모델과 토크나이저, 벤치마크를 모두 공개해 후속 연구와 기술 자립 기반을 제공했다”고 말했다.
Llama-Thunder-LLM은 한국어 벤치마크에서 기존 동급 모델 대비 가장 높은 성능(평균 65.0점)을 기록했으며, 영어 성능도 동급 모델과 유사한 수준을 달성해 한국어·영어 이중 언어 모델로서의 경쟁력을 입증했다.
서울대 연구팀의 성과는 대규모 자본 없이도 한국어 LLM을 개발·활용할 수 있는 기술적 토대를 제공했으며, 향후 중소기업과 대학의 한국어 AI 응용 프로그램 개발 활성화에 기여할 것으로 기대된다.
 기사 정정 / 반론
저작권자(c)산업종합저널. 무단전재-재배포금지
기사 정정 / 반론
저작권자(c)산업종합저널. 무단전재-재배포금지
관련뉴스
많이 본 뉴스
페로브스카이트 ‘대량 생산 역설’ 풀었다… 韓 연구진, 차세대 디스플레이 소부장 ‘독립’ 선언
차세대 디스플레이 시장의 ‘게임 체인저’로 불리면서도 양산의 기술적 난제에 가로막혀 있던 ‘페로브스카이트(Perovskite)’가 상용화의 임계점을 넘었다. 국내 연구진이 기존 고온 공정의 통념을 깬 ‘극저온 합성법’을 통해 품질 저하 없는 대량 생산 길을 열었기 때문이다. 이는 단순한 기
9년 집념이 뚫은 ‘물의 성배’… 영하 60℃서 액체 임계점 첫 포착
인류가 수백 년간 풀지 못한 물의 미스터리가 지난 24일 정부세종청사서 열린 합동 브리핑을 통해 세상에 공개됐다. 조종영 과학기술정보통신부 기초연구진흥과장의 소개로 시작된 발표는 김경환 포항공대 교수의 학술적 증명과 유선주 박사과정생의 현장 목소리로 이어지며 물의 근원적 비밀을 입체
원자 한 층에 갇힌 자성, 70년 난제 풀고 양자 소자의 새 길을 열다
두께 1나노미터(nm)도 채 되지 않는 원자 한 층의 평면 위에서 나침반처럼 자성을 띠는 입자들이 나란히 정렬한다. 수많은 원자가 입체적으로 쌓여야만 유지되던 자석의 성질이 극한의 2차원 평면에서 구현되는 순간이다. 과학기술정보통신부는 20일 오전 박제근 서울대학교 물리천문학부 교수 연구
안경 없이 2D·3D 전환…국내 연구진, 초광시야각 메타렌즈 디스플레이 세계 첫 구현
과학기술정보통신부는 22일 세종에서 브리핑을 열고, 포항공과대학교(포스텍) 노준석 교수 연구팀과 삼성전자 삼성리서치가 하나의 디스플레이에서 안경 없이 2차원(2D)과 3차원(3D) 화면을 전환할 수 있는 초박형 메타렌즈 디스플레이를 세계 최초로 구현했다고 밝혔다. 기존 3D 디스플레이의 두꺼운
"사이버 범죄, 산업화된 시스템으로 진화…"
글로벌 네트워크 보안 기업 포티넷코리아가 사이버 범죄가 개별 공격에서 산업화된 시스템으로 진화했다며, 범죄 인프라 자체를 해체하는 예방 전략이 필요하다고 강조했다. 포티넷코리아는 28일 서울 강남구 본사에서 김영표 이사 주재로 '2026년 글로벌 위협 동향 보고서'를 공개하고, 현대